

The Shift to Mission-Critical AI Systems
The nature of technical friction has fundamentally changed. In this new era, system reliability is no longer just about model accuracy or server uptime.
AI systems might return technically “successful” responses like HTTP 200s, low latency, green dashboards. However, they may still produce hallucinated answers, leak sensitive information, or follow flawed reasoning paths.
This creates a dangerous gap between system health and system behavior.
To govern, trust, and scale AI in production, enterprises need more than traditional monitoring. Adopt query tracing as the essential missing layer to make AI systems end-to-end observable, debuggable, and accountable.
Because in enterprise environments, you cannot govern what you cannot observe.
What Is Query Tracing?
Query tracing is the practice of capturing end-to-end visibility into how a single AI request flows through the entire system, from user input to final output and across models, tools, data sources, and decision logic.
At its core, query tracing reconstructs the full execution path of an AI interaction as a coherent, inspectable narrative.
A complete query trace captures:
Inputs and Prompts: The exact instructions and context sent to the model
Model Invocation: Specific model versions, parameters, and raw responses
Tool and API Invocations: Parameters sent to external databases or search tools, and the raw data returned
Intermediate Reasoning: The step-by-step "Chain of Thought" the agent followed before reaching its final output
Why Traditional Observability Falls Short for AI
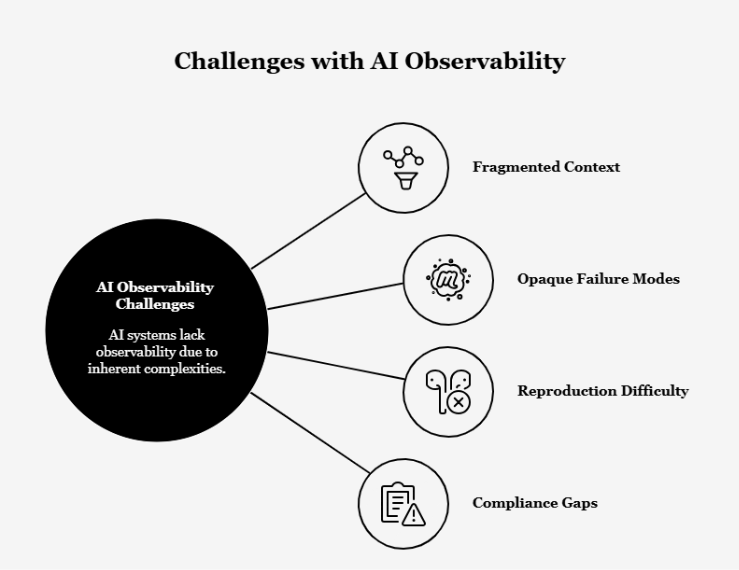
Standard Application Performance Monitoring (APM) tools were designed for deterministic systems where behavior is predictable.
But when applied to AI, these tools encounter several critical blind spots:
Fragmented Context: Traditional logs are scattered across different services, making it nearly impossible to piece together why a multi-step agent workflow failed.
Opaque Failure Modes: APM metrics like CPU and memory utilization are "context-blind." In AI, high latency might indicate a deep, successful reasoning process, while low latency could signal a shallow hallucination.
Reproduction Difficulty: Without tracing the exact prompt and retrieved context at the time of failure, developers cannot reproduce or fix non-deterministic errors.
Compliance Gaps: Regulated environments require a complete audit trail of how decisions were reached, something that isolated model metrics cannot provide.
As a result, many AI systems today are operationally opaque even when they appear healthy.
Core Components of Query Tracing
To be effective, an enterprise query tracing layer must include:
Trace IDs and Correlation: A unique identifier that links all operations from user input to final response into a single story.
Prompt and Context Capture: Recording the "ground truth" of what the model saw to distinguish between retrieval failures and model reasoning errors.
Model Invocation Tracking: Monitoring specific versioning and token-level probabilities to detect drift.
Tool and Data Lineage: Capturing the parameters and payloads of every external tool call to ensure data integrity.
Latency and Cost Attribution: Aggregating token usage across every model and tool call to provide a cost for every run.
Outcome and Feedback Capture: Linking user feedback directly to the trace for continuous improvement.
From Model Metrics to System Observability
Organizations often begin their AI journey by monitoring isolated model metrics such as accuracy, latency, or token usage. While necessary, this approach provides only a narrow view of system behavior.
As AI becomes embedded within complex, multi-component workflows, observability must extend beyond individual models.
As AI systems mature, observability evolves through distinct stages:
- Model-centric monitoring focuses on the performance of individual models in isolation.
- Service-level observability tracks system health indicators such as uptime, errors, and throughput
- Query tracing delivers end-to-end visibility, revealing how a single request propagates across models, tools, data sources, and decision logic in real production workflows.
This progression reflects a fundamental shift. AI is not deployed as standalone models but as part of interconnected systems. True reliability emerges only when the entire system is observable.
Real-World Use Cases Enabled by Tracing
Query tracing transforms AI from a "black box" into an operational system under control:
- Engineers can pinpoint exactly where an agent's logic veered off course, whether due to a misinterpreted prompt or malformed data from a tool.
- Traces reveal whether a bad answer was caused by poor document retrieval, improper chunking, or the LLM's inability to synthesize the provided context.
- In finance or healthcare, tracing provides the mandatory audit trail required by 2026 regulations to prove that AI followed approved policies.
- By identifying high-cost, low-value reasoning patterns, enterprises can optimize their orchestration logic to reduce runaway token bills.
How to Observe AI Behavior?
Key Design Principles for Enterprise Tracing
Effective enterprise-grade tracing must be built on the following foundations:
End-to-End Correlation: Signals must be linked across heterogeneous stacks from the UI to the vector database and the model gateway.
Standardization via OpenTelemetry: Using vendor-agnostic standards ensures that telemetry data is portable and compatible with modern observability backends.
Security and Privacy: The system must automatically redact Personally Identifiable Information (PII) from prompt payloads before they are stored or processed by external vendors.
Human-Readable Traces: Traces must be presented in a way that allows developers and auditors to quickly interpret the agent's reasoning without manual log stitching.
Challenges and Risks to Address
While essential, query tracing introduces new operational challenges:
Data Volume: AI traces are significantly larger than traditional traces; an average AI span can be 50KB, and complex agent traces can reach 10GB or more.
Performance Overhead: Capturing detailed metadata can increase latency. High-volume environments may require using OpenTelemetry Collectors or sampling to manage throughput.
Signal-to-Noise Ratio: Large-scale systems generate massive amounts of telemetry. Advanced platforms must use pattern clustering and anomaly detection to surface meaningful failures.
The Future of AI Observability
By 2026, query tracing will become as foundational to the enterprise as compute and storage.
Future platforms will move beyond narrative logs toward Cognitive Observability, capturing raw internal activation profiles and model confidence metrics to predict failures before they happen. Tracing will integrate directly with automated evaluation loops, where production traces are used to constantly refine prompts and retrain models in a virtuous cycle of improvement.
Conclusion
The transition of AI from experimental pilot to mission-critical infrastructure requires uncompromising accountability. Enterprises must trust AI to consistently deliver reliable business outcomes.
Query tracing transforms AI from being unexplainable to a transparent, manageable operational system. It delivers explainability, auditability, and trust, and crucial benefits for adopting AI at a scale.
PromptX is an enterprise-grade AI Knowledge Navigator designed to bring traceability, governance, and system-level visibility to AI interactions so enterprise teams can deploy AI with confidence, compliance, and control.
Learn how PromptX operationalizes trustworthy AI. Get in touch today.
.png)
.png)
.png)



