

Generative AI has reached a pivotal inflexion point. What began as a season centred on a model’s ability to pen poetry or pass the Bar Exam has matured into a disciplined engineering challenge. As organisations move from "Can the model do this?" to "Can we run this at scale?", the traditional benchmarks of data science are proving insufficient.
For decades, AI evaluation was a sanctuary of academic metrics: Accuracy, Precision, Recall, and F1 Scores. While these remain vital for model validation, they offer little guidance for a CTO managing a production environment or a CFO reviewing a cloud bill. In 2026, the discourse has shifted. The maturity of Agentic AI and Large Language Models (LLMs) has introduced a new triumvirate of operational performance: Tokens, Latency, and Cost.
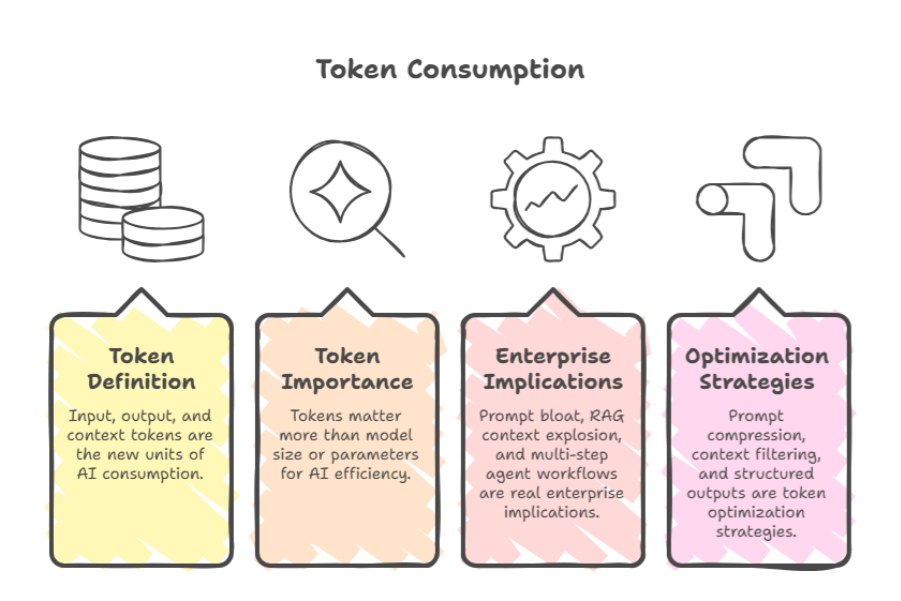
1. Tokens: The New Unit of AI Consumption
In the era of Generative AI, the "row" or "record" has been superseded by the token. Representing approximately 0.75 words, tokens are the fundamental atoms of atomic computation. However, for the enterprise, tokens are no longer just linguistic units; they are the primary lever of system performance.
- The Context Explosion: In 2026, context windows have expanded to millions of tokens, allowing entire codebases or legal archives to be processed at once. Yet, this "infinite" capacity is a double-edged sword. Enterprises now grapple with Prompt Bloat, where inefficiently constructed instructions consume 30% of the budget without adding marginal utility.
- RAG and Agentic Overheads: Retrieval-Augmented Generation (RAG) and multi-step agent workflows have turned token management into a high-stakes game. A single user query in an agentic system can trigger a recursive loop of "thought" tokens and tool-call tokens, leading to an exponential increase in consumption that traditional monitoring tools often miss.
- Optimisation Strategies: Leading engineering teams are moving toward Context Filtering using smaller, specialised models to summarise data before passing it to a frontier model and Structured Outputs, which force models to respond in compressed formats like JSON or Protocol Buffers to minimise "chatter."
2. Latency: When AI Becomes Part of the User Experience
For a PoC, a ten-second wait for a response is a curiosity. In a production Copilot or a customer-facing agent, it is a failure. As AI integrates into real-time software, Latency has become the ultimate arbiter of user adoption.
Enterprise latency is rarely just about the model's "time to first token." It is a composite of three distinct layers:
- Model Inference: The raw compute time required for the LLM to generate text.
- Network and Orchestration: The overhead of routing requests through API gateways and security guardrails.
- Tool and Database Latency: The time taken for an agent to query a vector database or execute a Python script.
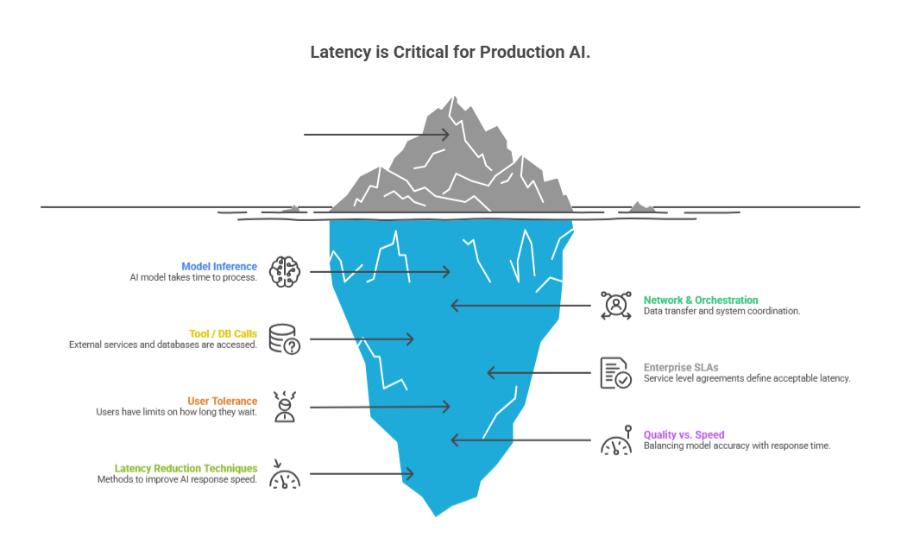
Current benchmarks suggest that, for "human-in-the-loop" applications, a total latency exceeding 2 seconds results in a 40% drop in user engagement. To combat this, 2026 architectures heavily utilise Speculative Decoding (using a tiny model to guess the big model's output) and Semantic Caching, where previous answers to similar questions are stored and served instantly, bypassing the model entirely.
3. Cost: From Experimentation to CFO Scrutiny
As deployments scale to tens of thousands of users, AI costs have shifted from experimental R&D budgets to standard Cost of Goods Sold (COGS).
The complexity of AI pricing goes beyond a simple price-per-token. Enterprises now face a "Hidden Cost Stack":
- The Retry Tax: Hallucinations or failed tool calls often require the system to run the same prompt three times to get one correct result, tripling the projected cost.
- Observability and Guardrails: Running safety layers (such as PII redactors or toxicity filters) can add 15-20% overhead to every request.
- The Human-in-the-Loop: In high-stakes, regulated industries, the cost of a human auditor to verify AI outputs often exceeds the computational cost of the AI itself.
To maintain margins, enterprises are adopting Model Routing. Instead of sending every query to a "Frontier" model (like GPT-4 or Claude 3.5), they use a "Router" to send 80% of simpler tasks to lightweight, open-source models (like Llama 3 or Mistral), reserving the expensive models only for complex reasoning.
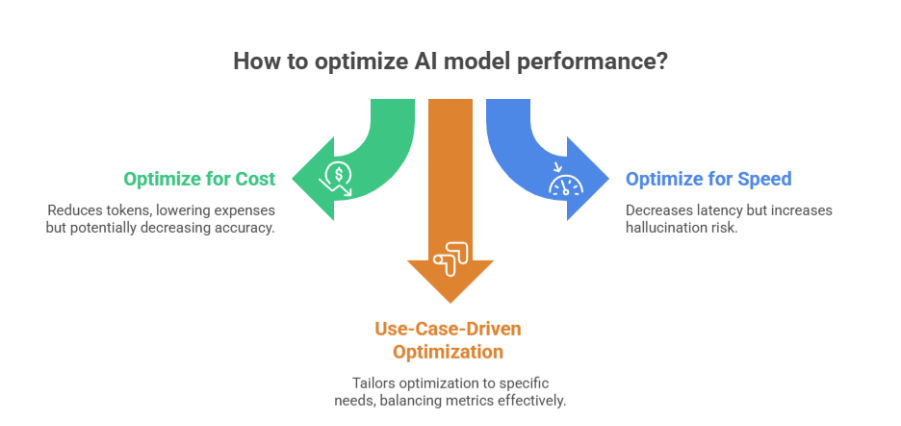
4. The Trade-Off Triangle: Token vs Latency vs Cost
The central challenge of AI engineering is that these three metrics are constantly in tension. Optimising one almost invariably degrades the others.
For example, a legal agent requiring 100% accuracy may use Chain-of-Thought reasoning. This produces more tokens and higher latency but ensures correctness. Conversely, a customer service chatbot might prioritise low latency and low cost, sacrificing deep reasoning for speed. There is no "perfect" configuration; there is only the right configuration for the specific business outcome.
5. Monitoring the New Metrics
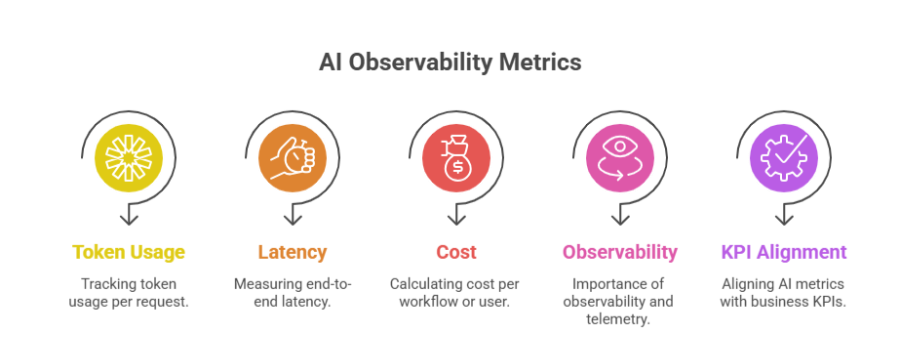
In 2026, the "AI Dashboard" has evolved. Leading enterprises are no longer looking at static charts; they are instrumenting their AI stacks with the same rigour as high-frequency trading systems. Key performance indicators (KPIs) now include:
- Cost per Resolved Workflow: Measuring the total spend required to actually solve a customer problem, rather than just the cost per query.
- Tokens per Outcome: A measure of "intellectual efficiency", how much compute was required to reach the correct answer?
- P99 Latency: Ensuring that even the most complex agentic loops don't leave the user hanging for more than a few seconds.
By aligning these technical metrics with business KPIs such as Customer Satisfaction (CSAT) or Reduction in Support Tickets, organisations can finally calculate a true Return on Investment (ROI) for their AI spend.
Conclusion: AI Success Is an Engineering + Finance Problem
The transition of Generative AI from a novelty to a utility is complete. We have moved past the era of "Can it?" and into the era of "At what price and how fast?"
Enterprises that approach AI solely as a data science initiative may encounter challenges such as unpredictable costs and performance inefficiencies. In contrast, those that treat AI as a disciplined engineering and financial practice, with a focus on optimizing token usage, reducing latency, and maintaining strong cost governance, are more likely to integrate AI effectively and sustainably into their operations.
See how PromptX operationalises these principles to deliver truly context-aware, efficient enterprise search. Get in touch now.
.png)
.png)
.png)



