

The problem nobody can see
Every large organisation carries an invisible liability: the distance between its documented processes and the behaviour of its live systems. Process maps describe an orderly world. The estate underneath tells a messier story — data that flows to systems no one remembers, fields assumed to be reliable that are 40% empty, business rules locked inside code written decades ago. In a routine year this gap is tolerable. During a major transformation it becomes the single largest source of delays, cost overruns and reduced ambition.
The conventional response is to throw analysts at the problem: months of interviews, spreadsheets and manual tracing. It is slow, it doesn't scale, and the knowledge it produces evaporates the moment the consultants leave. The alternative — pure automation — scans fast but produces a catalogue with no business meaning. Neither approach, on its own, gives a transformation programme what it actually needs: a trustworthy, evidence-based picture of reality that people can act on.
The core insight
Data discovery is not a tooling problem or a workshop problem. It is a reconciliation problem. The value lies in systematically comparing the business hypothesis against the technical ground truth — and treating every discrepancy as a finding.
A hybrid by design, not by accident
VE3's methodology is deliberately a 'Human-plus-Machine' model. Automation does the heavy lifting — typically 70 to 80% of the foundational work — scanning the estate, extracting lineage and profiling quality at a scale no team of analysts could match. Human expertise supplies the remaining, decisive 20 to 30%: business context, risk judgement and the interpretation that turns raw metadata into meaning.
Rather than forcing a single rigid process onto every programme, the framework deploys one of three proven implementation patterns depending on the data and the risk profile:
- Automation-first with human review. An automated scan, classification and lineage extraction provides the baseline, then human stewards and business experts validate it, review high-risk items and add context.
- Stratified approach. Data is tiered. Critical data — taxpayer master records, for example — receives intensive manual discovery and validation; important data gets automated discovery with human review; low-risk data is processed with full automation.
- Iterative refinement. A broad automated discovery runs first, experts validate a sample, their feedback refines the automated rules, and the discovery re-runs — continuously improving accuracy across the enterprise.
The five phases of discovery
At the heart of the approach is a five-phase, iterative engine. Each phase answers a different question, and the phases build on one another to converge on a single validated view.
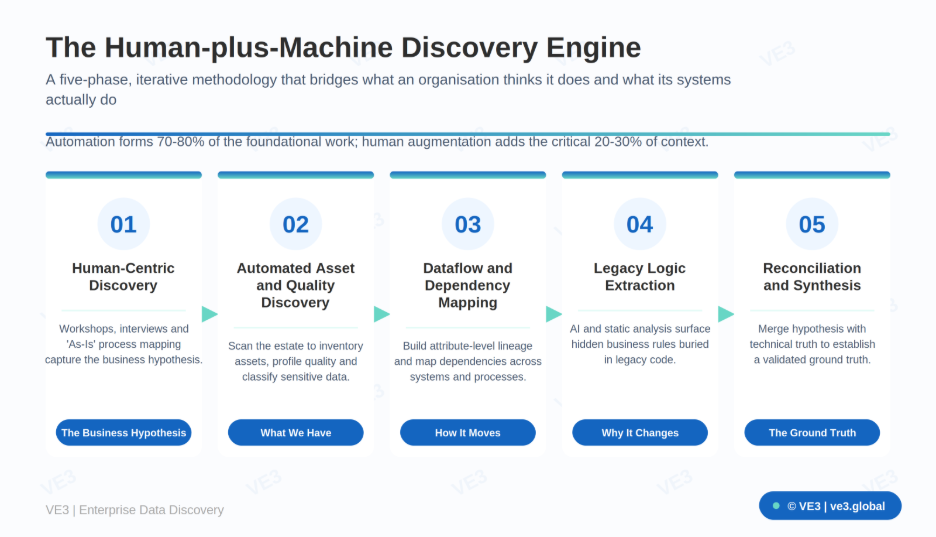
Phase 1 — Human-centric discovery: the business hypothesis
Skilled facilitators acting as Data Translators run structured workshops with managers and subject-matter experts to capture the 'As-Is' process, its known data, controls and risks. Crucially, this output is treated as a testable hypothesis, not the final truth. Techniques include 'As-Is' and 'To-Be' process mapping, persona development, journey mapping, targeted interviews and documentation review. The primary output is a draft BPMN 2.0 model and a seed-level business glossary.
Phase 2 — Automated asset and quality discovery: what we have
Data engineering teams configure automated discovery tools to scan the relevant estate — from legacy mainframes to cloud platforms — extracting technical metadata and tracing data at column level. Profiling runs across three dimensions: structure discovery (formatting and consistency), content discovery (nulls, duplicates, outliers and rule violations) and relationship discovery (keys, dependencies and orphaned records). Automated classification then tags sensitive data wherever it physically resides.
Phase 3 — Dataflow and dependency mapping: how it moves
This phase builds the lineage map that everything downstream depends on. The target is usually attribute-level lineage — column-to-column mappings — because that is what makes true impact analysis possible. Teams use a hybrid of techniques: automated lineage extraction from ETL and SQL code, pattern-based inference where code isn't accessible, native metadata capture from modern platforms, and log or traffic analysis to catch undocumented transfers.
Phase 4 — Legacy logic extraction: why it changes
The hardest knowledge to recover lives inside legacy code — tax calculations, validation logic and business rules with no documentation. Business Rule Extraction combines static code analysis with AI and natural-language processing to surface rule-dense areas and translate them into plain-language rules and decision tables. This is not a magic button: large applications take time, and AI recovers the code's logic while humans must still supply the business intent behind it.
Phase 5 — Reconciliation and synthesis: the ground truth
This is where the real discovery happens. The Data Translator leads a 'Visual Diff' workshop, presenting the BPMN 2.0 hypothesis alongside the automated lineage and profiling results. Walking stakeholders through the mismatches is what uncovers the 'unknown unknowns' that sink programmes.
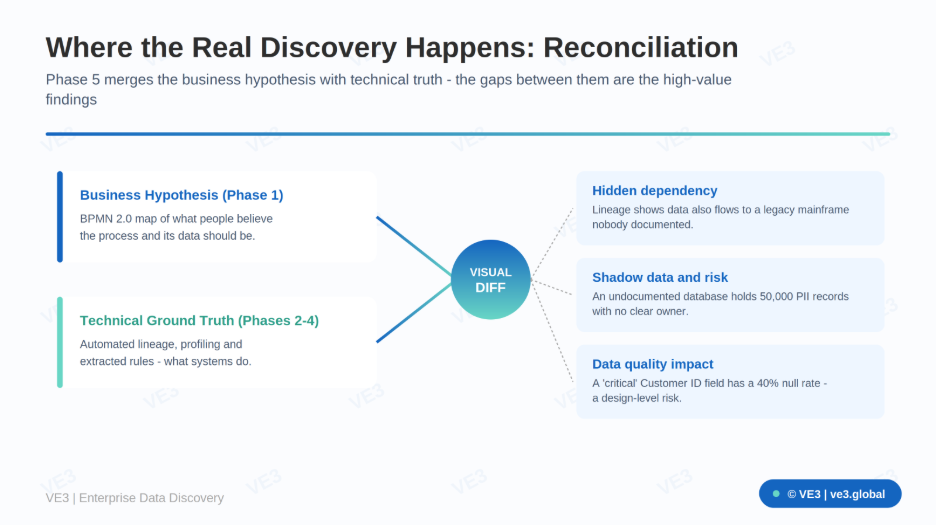
Typical findings look like this: lineage shows data flowing to a legacy mainframe that the process map never mentions; an asset scan finds an undocumented database holding tens of thousands of PII records with no clear owner; a field the business calls 'critical' turns out to have a 40% null rate. Each gap is a risk identified before it becomes a blocker.
What you are left with
The output of the engine is not a static report destined for a shelf. It is a set of trusted, reusable assets:
- A validated, enriched BPMN 2.0 process model corrected against technical reality.
- A validated business glossary, with business terms formally linked to the physical data assets that represent them.
- A definitive list of dataflows, dependencies and risks, ready for ingestion into enterprise tooling.
The bottom line
A hybrid model that systematically reconciles the business view with the technical reality doesn't just document the estate — it de-risks the transformation. The discrepancies you surface in a workshop are the cost overruns you avoid in delivery.
In the articles that follow, we look at how this validated knowledge is operationalised — the federated tooling model that keeps it alive, the dynamic impact analysis it enables, and the governance that turns a one-off exercise into a permanent capability.
VE3 helps organisations design and operate Human-plus-Machine data discovery at enterprise scale — pairing automation with expert Data Translators to turn complex, federated estates into trusted, reusable knowledge. To explore how VE3 can de-risk your transformation, visit ve3.global or speak to our Data & AI team.
.png)
.png)
.png)



