
MatchX transforms fragmented, inconsistent, and unstructured data into a trusted foundation for AI, analytics,
and enterprise operations. From ingestion to governance, every stage of the data lifecycle is intelligently automated.
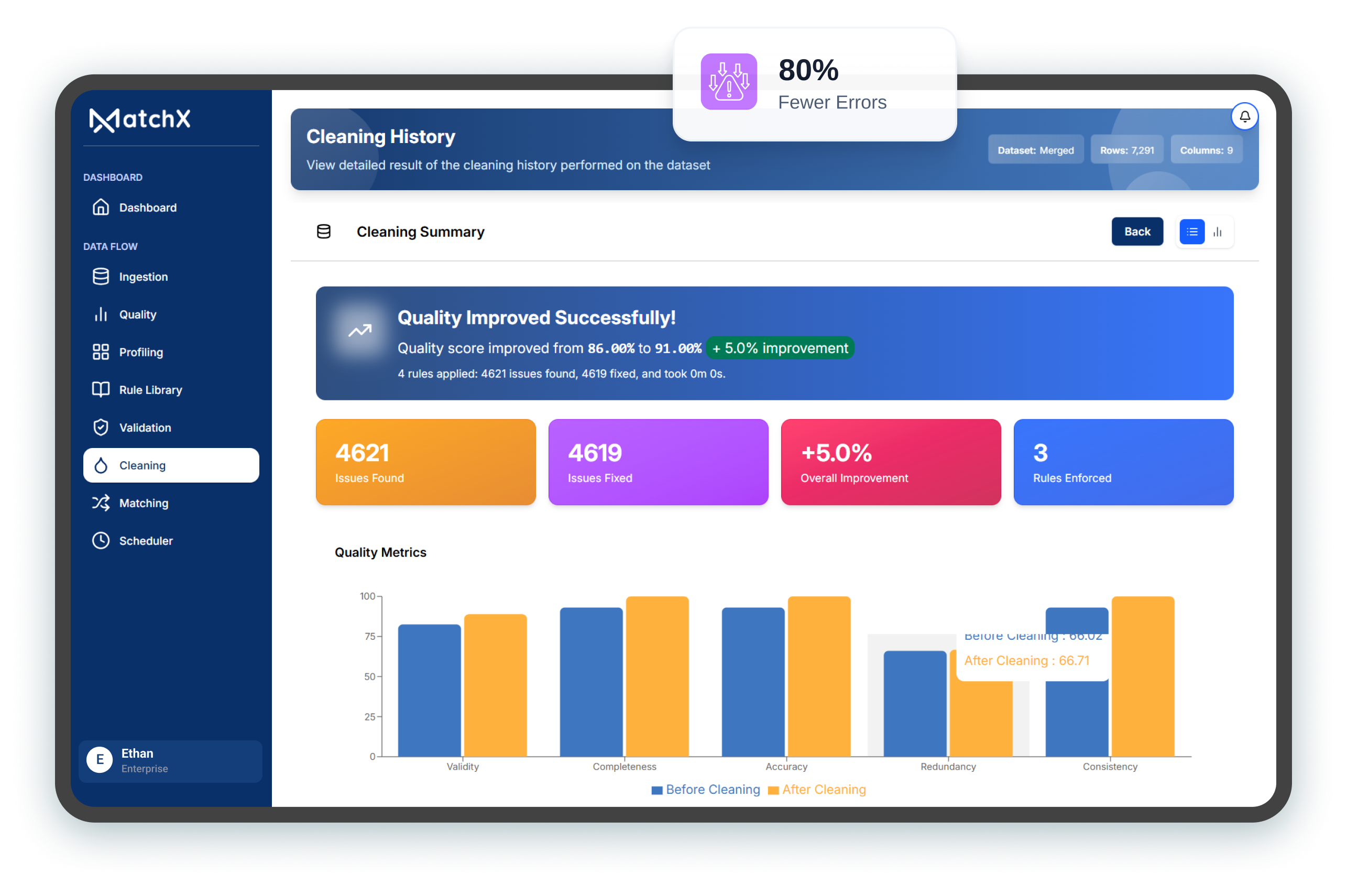
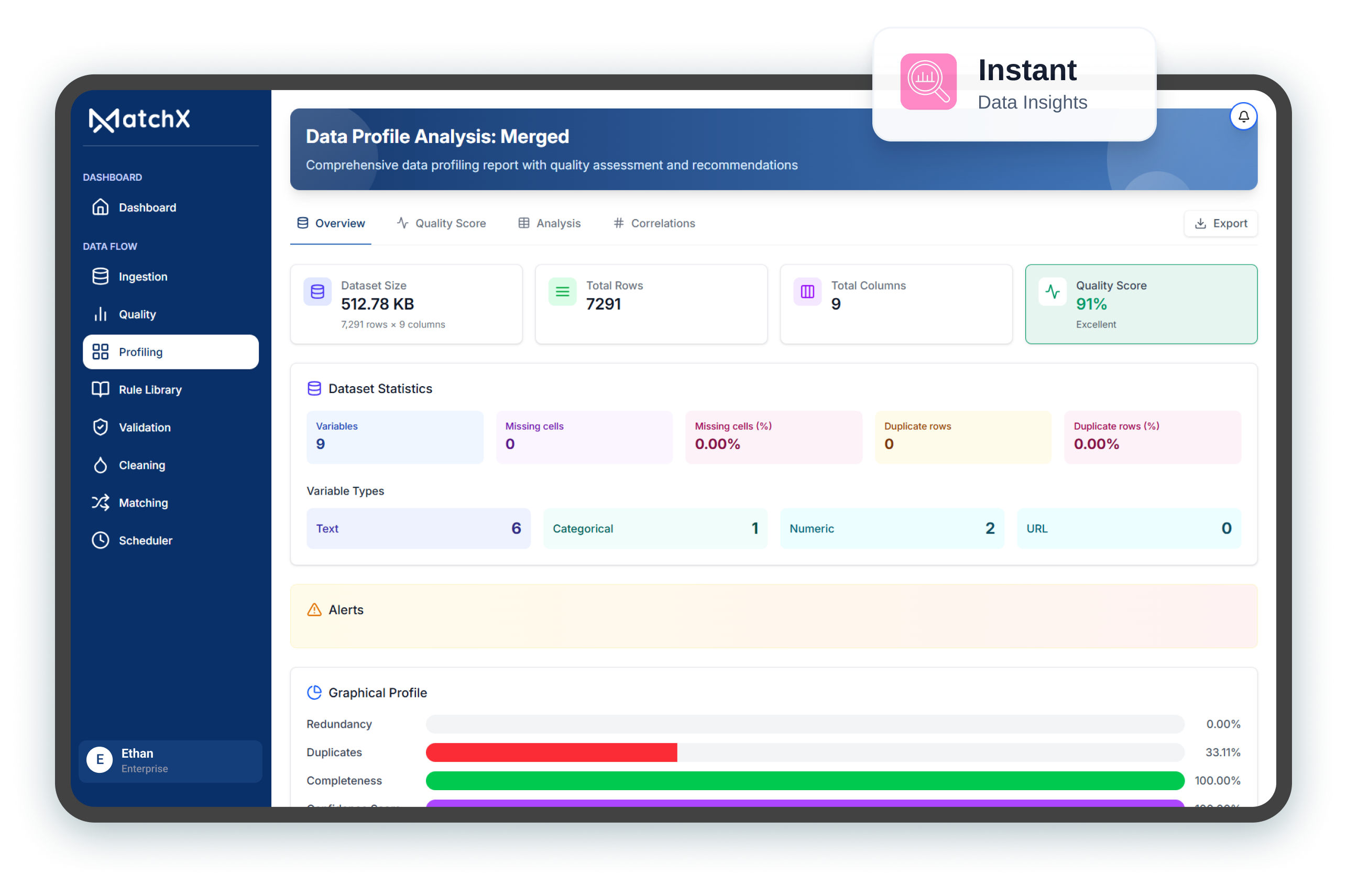
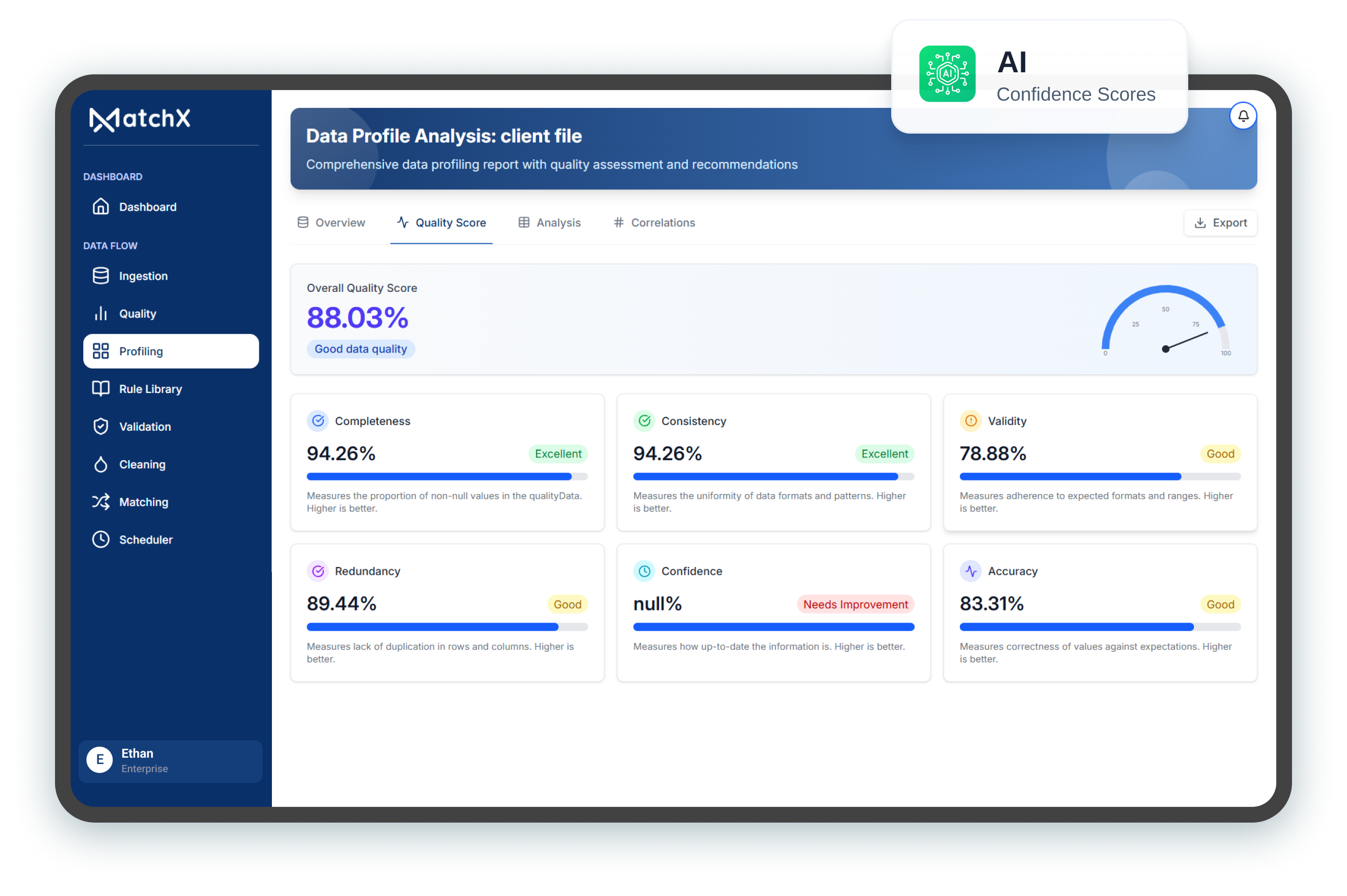
Autonomous agents now detect inconsistencies, apply rule-based transformations, reshape fields,
and reduce manual rule configuration across large datasets.
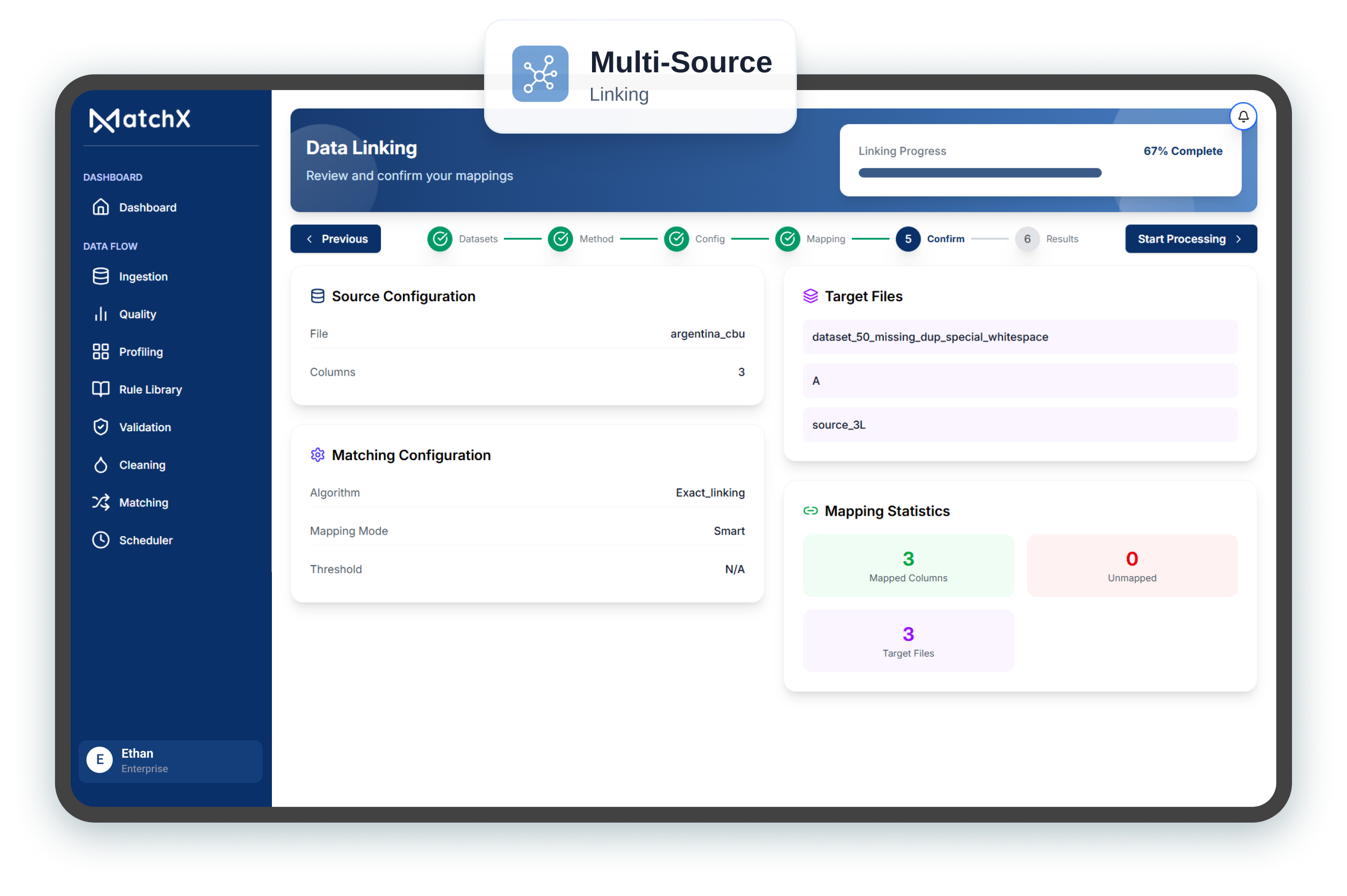
Resolve complex parent–child structures across enterprise hierarchies, supplier networks, and
multi-level organizational systems.

Enable signature-level verification for document-linked identity validation, enhancing fraud detection and compliance workflows.

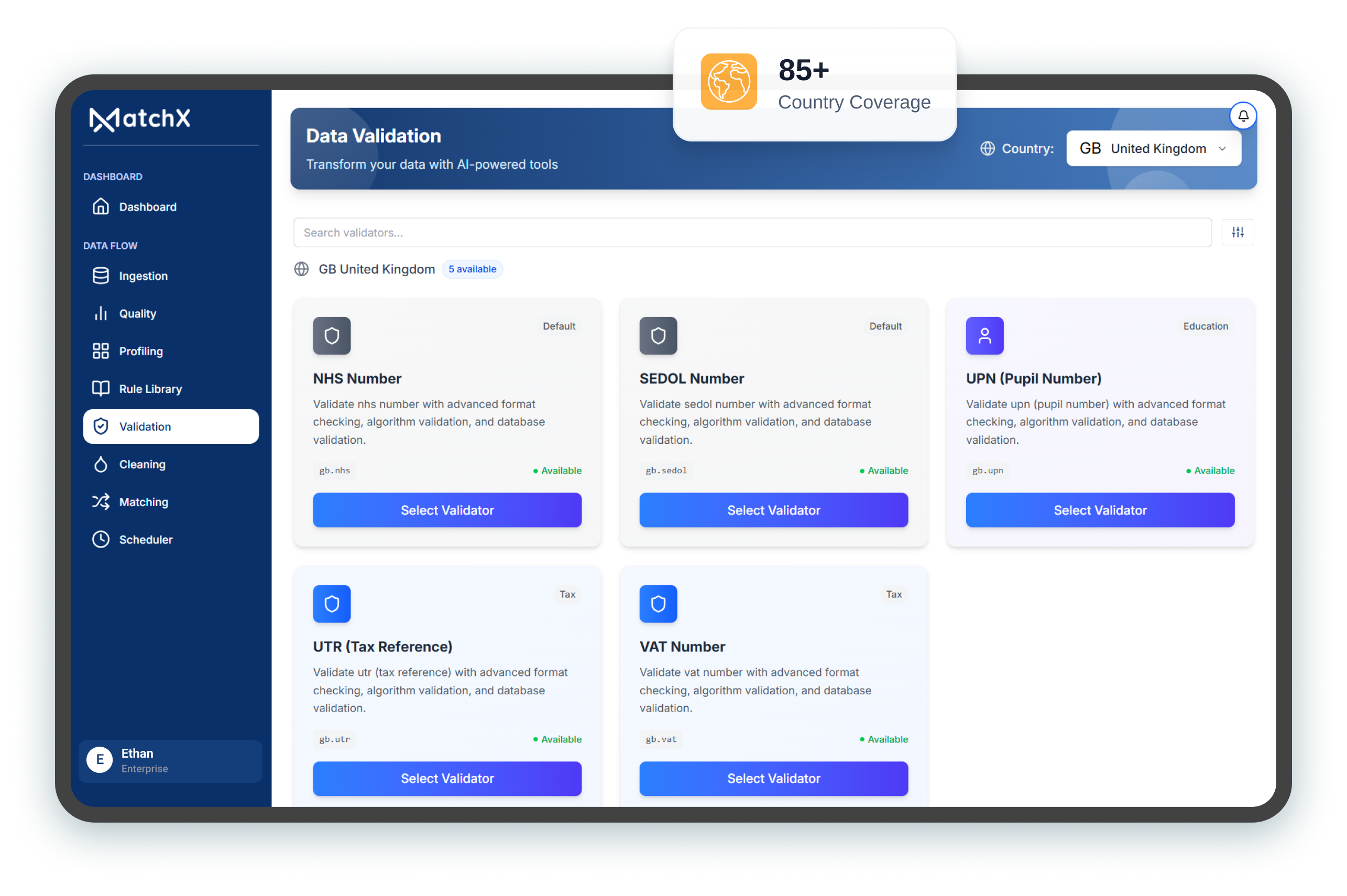
Standardize and validate global address formats, detect inconsistencies, and strengthen match accuracy in customer and citizen datasets.

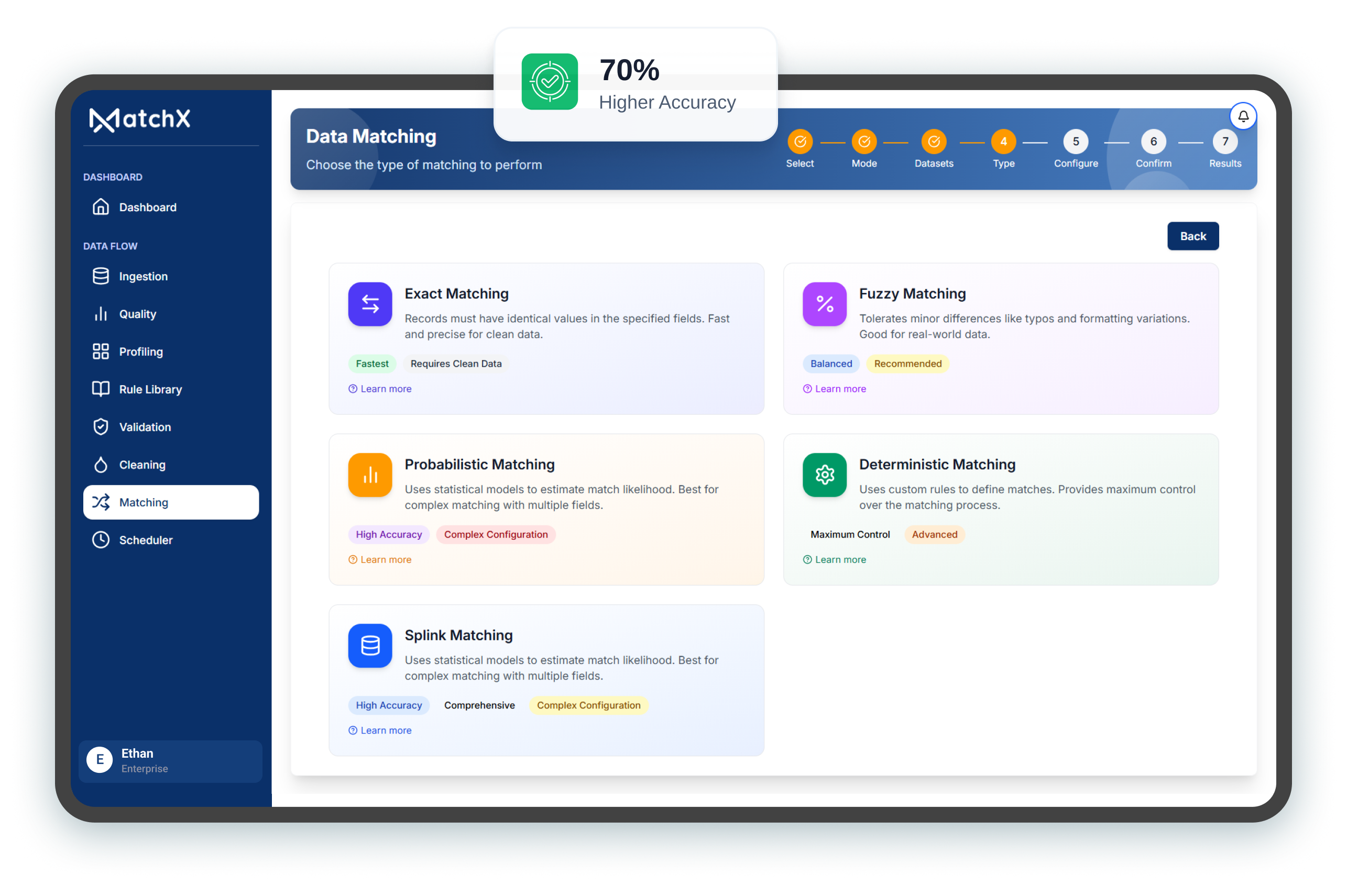
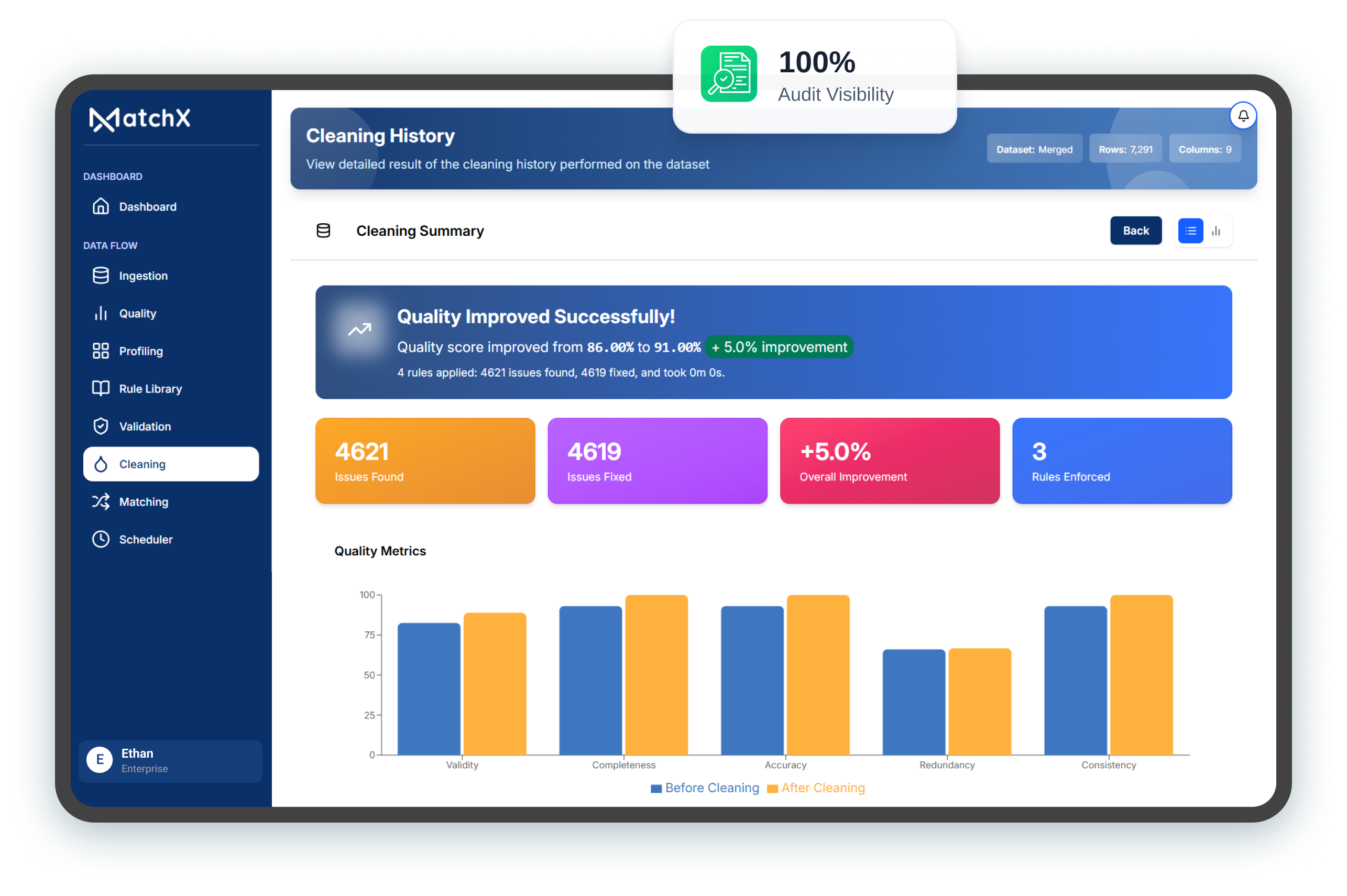
Improved deterministic + probabilistic logic delivers stronger reconciliation across BFSI, Government, and Healthcare use cases.
Expanded automation reduces manual intervention while accelerating enterprise data preparation and
AI-readiness.
Every feature in MatchX is designed to tackle the toughest data challenges — from ingestion to validation to approval.
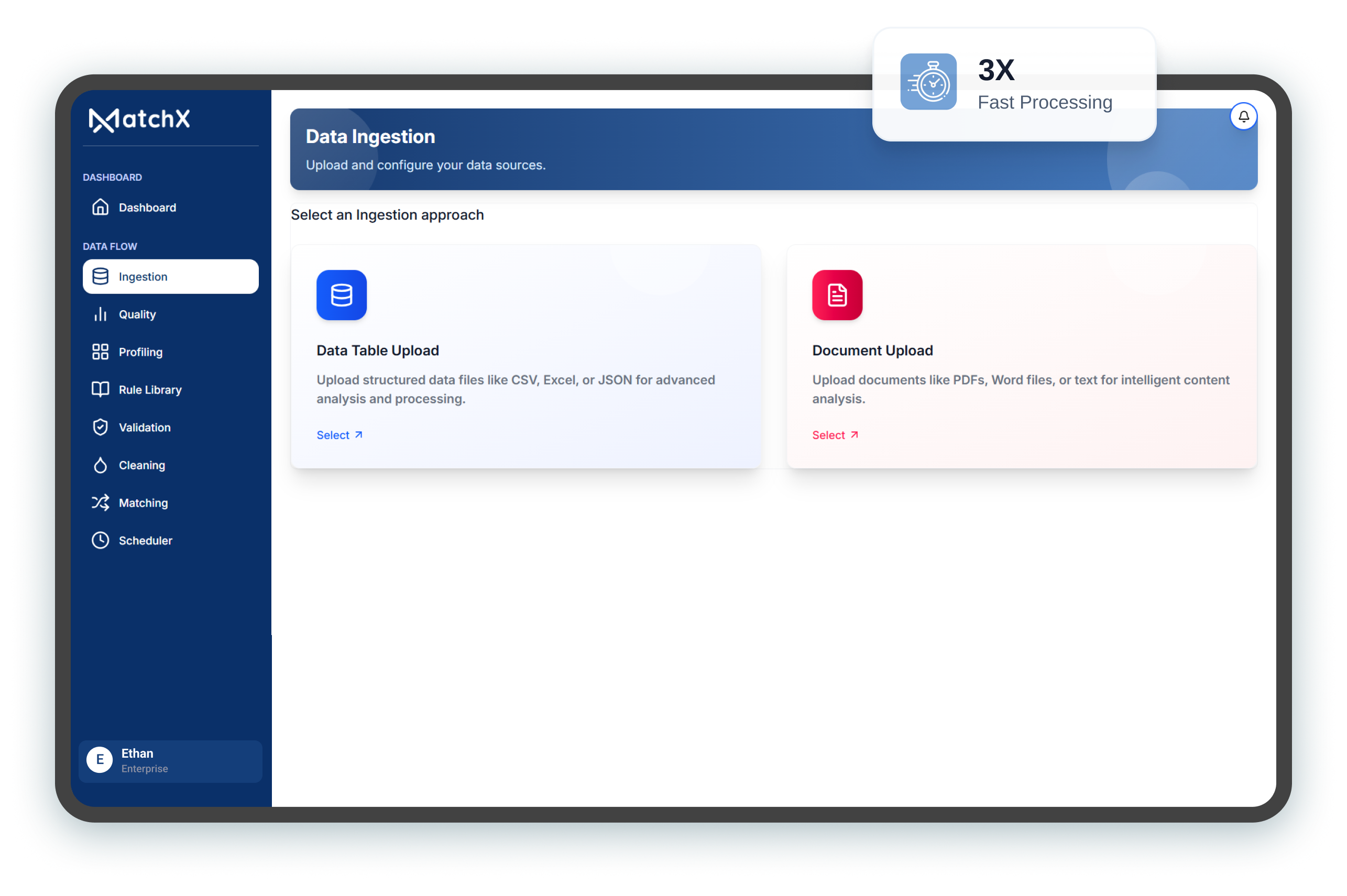
Powered by optimized PySpark pipelines, MatchX supports large-scale ingestion through batch and real-time processing. Faster uploads, optimized long-running jobs, and enterprise scalability ensure seamless handling of high-volume datasets.
Powered by optimized PySpark pipelines, MatchX supports large-scale ingestion through batch and real-time processing. Faster uploads, optimized long-running jobs, and enterprise scalability ensure seamless handling of high-volume datasets.
Powered by optimized PySpark pipelines, MatchX supports large-scale ingestion through batch and real-time processing. Faster uploads, optimized long-running jobs, and enterprise scalability ensure seamless handling of high-volume datasets.



